作者: 有猫万事足 原文来源: https://tidb.net/blog/772a4767
前言
经过之前的4篇,其实总体的报表相应时间已经从小时级别到了分钟级,有新的报表需求,基本很快都能解决。
https://tidb.net/blog/f6bc5537
https://tidb.net/blog/666ab16d
https://tidb.net/blog/15d0fbf6
https://tidb.net/blog/26695303
从老板的角度看原有的问题已经解决了,但我个人还是抱着尝试的心态,体验了一下TiFlash。这一体验就再也没有停下。 TiFlash因为没有成本,被我和其他系统的测试服挤2台4c8g。涉及TiFlash的主要是日志表,这种表比较大,相关的AP业务也比较多。当mpp运行需要用到其他小表的时候,再一点点的给小表添加TiFlash副本。
1,使用TiFlash的最佳场景
TiFlash能让我用了就离不开的一个最主要的原因就是因为它对聚合计算的加速特别明显,能轻松比TiKV+索引的方式快2-10倍。 聚合计算体现在sql上,就是带group by的语句。可以说只要带group by的语句放到TiFlash上执行都会有个很大的提升。 当然不带group by直接全表聚合,类似 select count(1) from t这种,select后面只带聚合函数的sql也是聚合计算。
而TiFlash不擅长的是扫描行数据,比较典型的情况是从一个100+亿的表中根据条件找几百行的数据。这种任务TiFlash也可以做,但是不会有上面那种聚合计算的提升大。有的时候可能性能使不如TiKV+合适的索引查的更快的。
还有一类大量行扫描的任务就是导出数据,一般有了AP系统以后,为了不影响TP系统稳定,需要大量导出的时候就想从AP系统上导出数据。
而类似的情况在TiDB的架构下就会考虑是否可以从TiFlash导出,我也这么尝试过,结果是非常困难。如果是有些导出后还要再计算的情况,不妨考虑直接写成sql在TiFlash上算,可能都比导出的时间短。如果数据很多,甚至没法从TiFlash上导出。
1.1,TiFlash的MPP模式
对于MPP模式的详细介绍有很多。这个模式有一些运行的特点:多节点并行读取/计算,多个节点之间可以相互通信,交换数据。 落实到一个具体的sql上,我认为最重要的一点,就是可以让hashjoin运行在TiFlash上。 这是和原来PD,TiDB,TiKV这三件套组成的存算分离体系的一个显著的不同点。 在原来的存算分析体系下,TiDB负责计算,TiKV负责存储。一个hashjoin的运行是在TiDB上,join两边的行数据在TiKV上运行。 而在AP业务中一个带join的聚合计算,往往要扫描大量的数据,和复杂的计算,在没有MPP模式的情况下,这会同时给TiDB和TiKV都带来显著的压力,对原有的TP系统的稳定性造成威胁。 MPP模式执行这类sql,那么在这个模式下,TiDB节点差不多是直接从TiFlash上拿到计算好的结果,只有很少的计算,资源占比很小。
1.2,TiFlash+MPP情况下,好的执行计划的特征
要做到计算大部分下推到TiFlash上用MPP模式执行,TiDB只有少量计算。
这种执行计划有个显著的特征:
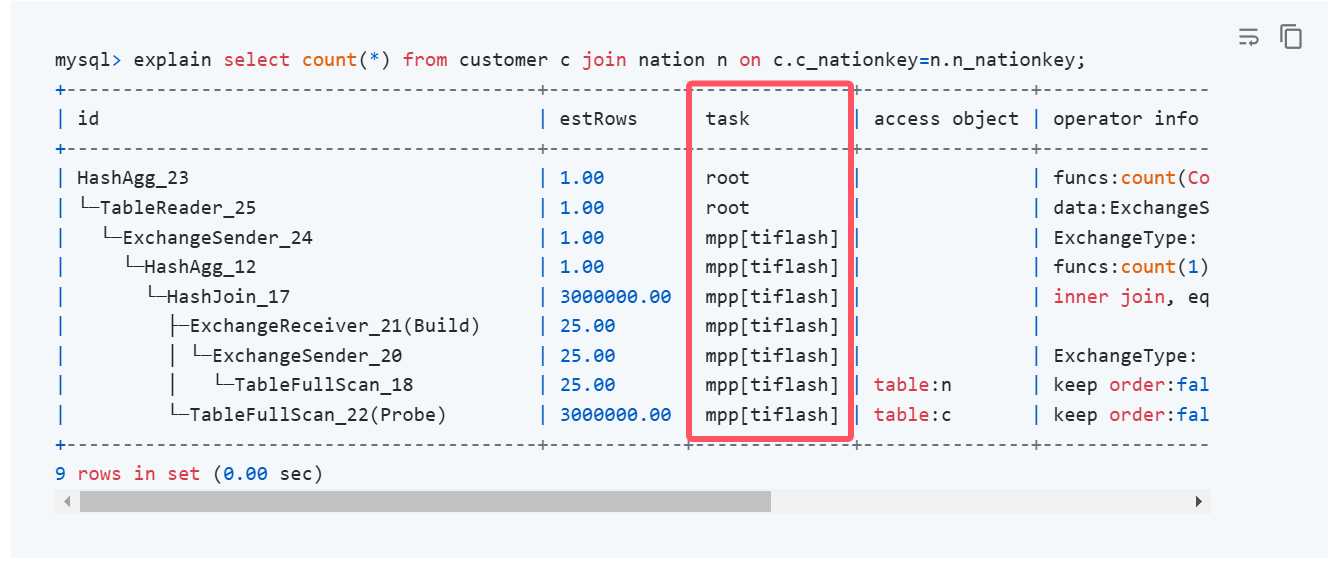
主要看执行计划中task这一栏,上面是几行root——代表TiDB做的少量计算,下面几行全是mpp[tiflash]——代表大部分计算是通过TiFlash+MPP模式来做的。
1.3 如何实现这个优化
我们现在有了一个带join的聚合计算sql,也了解到通过TiFlash+MPP的方式可以让这个sql运行的更快。那么该如何做到这一点? 和MPP计算相关的参数有2个:tidb_allow_mpp和tidb_enforce_mpp 当这两个参数是OFF的情况下就是任何情况都不使用mpp模式。 当tidb_allow_mpp=ON,tidb_enforce_mpp=OFF的时候,就是交给优化器判断是否可以使用mpp模式。 如果两个参数都是ON,则是要求优化器只要sql涉及到的表有TiFlash副本,就会使用MPP模式执行。 tidb_allow_mpp=OFF,tidb_enforce_mpp=ON,这个奇怪的组合也是可以的,但是这种参数设置组合等同于2个参数都是OFF,即在任何情况下都不使用MPP模式。
如果一个sql我们判断它属于聚合计算,又发现它没有走mpp的执行计划。这个时候需要定位不能MPP的原因,我们需要把这两个参数全部设置为ON,再去explian 这个sql,得到一个不走mpp的执行计划,再show warnings,就能看到不走mpp的原因。
特别需要注意的是,因为这两个参数对现有系统的影响比较大,如果你不小心设置global级别tidb_allow_mpp=ON,tidb_enforce_mpp=ON,会让原本系统中不该走TiFlash MPP的sql也走TiFlash MPP。 所以在定位问题的时候一定要seesion级别设置这2个变量。不然会对现有系统的稳定造成较大的冲击。
在导致不能MPP的原理里面,我想重点提一下动态分区裁剪这个参数
set @@session.TiDB_partition_prune_mode = 'dynamic'
我在论坛碰到的大部分不能MPP的主要原因都是这个参数,有些老的系统升级上来的时候发现动态分区裁剪会导致原有的执行计划发生变化,为了保险往往会关闭动态分区裁剪,而MPP模式恰好需要动态分区裁剪,调和这种矛盾的办法也是像上面这session级打开一下,或者通过 set_var 这个hint在sql语句执行的时候,临时修改一下这个参数。 set_var 这个hint需要7.5版本的支持。
2,TiFlash自身的稳定性管理
MPP模式在执行速度上会有明显的优势,但往往有更利的矛,你就想尝试用它对付更坚固的盾。 在一个需求刚开始做的时候,以及在临时发起的adhoc类查询中,首先需要面对的,就是内存容易OOM的问题。
2.1内存占用控制
执行速度的加快,会让人想尝试更大范围的聚合,大范围的聚合往往也会带来内存占用的快速上升。 为了让这类sql能运行过去,主要的办法是使用算子落盘。 有两种算子落盘的方式: 算子级落盘 (7.1版本), 查询级落盘 (7.5版本)。 算子级落盘需要单独设置3个内容占用高的算子的内存上限,这3个算子是sort,group by,join。 查询级落盘,则是根据真个语句占用的内存来计算内存上限。 明显查询级的落盘更好,我也主要介绍这种算子落盘的方式。 语句级的算子落盘主要涉及2个参数: tiflash_mem_quota_query_per_node——用于控制单个查询在单个TiFlash节点中的内存上限,超过这个限制TiFlash会报错并终止。 tiflash_query_spill_ratio——用于控制语句级落盘的阈值。当使用的内存超过tiflash_mem_quota_query_per_node*tiflash_query_spill_ratio,TiFlash会触发落盘。
当然如果你想告诉编写这些业务查询人员一个简单的数据量估算,可以推荐他们每次执行sql的时候先看看执行计划。 执行计划中有一栏estRows——这代表这个sql根据统计信息预估的某个算子需要处理的数据行数。假如你的统计信息是靠谱的,那么这个推算大致是比较符合预期的,起码不会有数量级的偏差。 让业务查询人员做这类查询的时候先看看estRows中的最大值,是个比较简单有效的快速预估处理数据规模的办法。 在我这个4c8g 2台TiFlash做MPP的情况下,我给业务人员推荐的estRows数值的最大值是6亿,如果estRows这一栏中最大的数字超过6亿——预估处理行数的超过6亿行,目前的机器配置不靠落盘是大概率运行不过去的。
2.2 并发控制
翻过了内存控制的山,下一个容易碰到的问题就是并发控制。 常见的现象,比如某个sql明明单独执行很快,但是生产系统上使用效果并不好。 如果发现是TiFlash+MPP的这种执行计划(上文1.2部分的内容),那就需要关注一下并发是不是高了。 TiFlash+MPP对聚合计算的加速效果很明显,但是并发一高性能退化的也快。 解决这个问题,主要手段是 查询结果物化 。
前面已经说了在TiFlash+MPP执行的情况下,负载主要在TiFlash这个列存节点上进行。查询结果物化的意思就是,让列存节点(TiFlash)中计算完成的结果保存到行存节点(TiKV)中。后续的访问就可以通过行存TiKV来访问这些结果。 这个思路和物化视图很像,差别可能仅在需要手动刷新,执行的速度由查询和插入2个时间组成。就查询而言,优化方式上面已经写了,就插入时间的优化,主要是防止insert into的表有写入热点。如果select中的数据在聚合后还是很大,有几万行以上,那么是需要考虑insert into的表是否存在写入热点的。 另外文档种这个查询结果物化中的例子是有点狭窄的。 insert into ... select ...这个语句第一次建立对应查询的物化结果的时候是有用的。但后续刷新就没法再用了。
经过个人测试和发帖确认,replace into也可以做到从查询结果物化
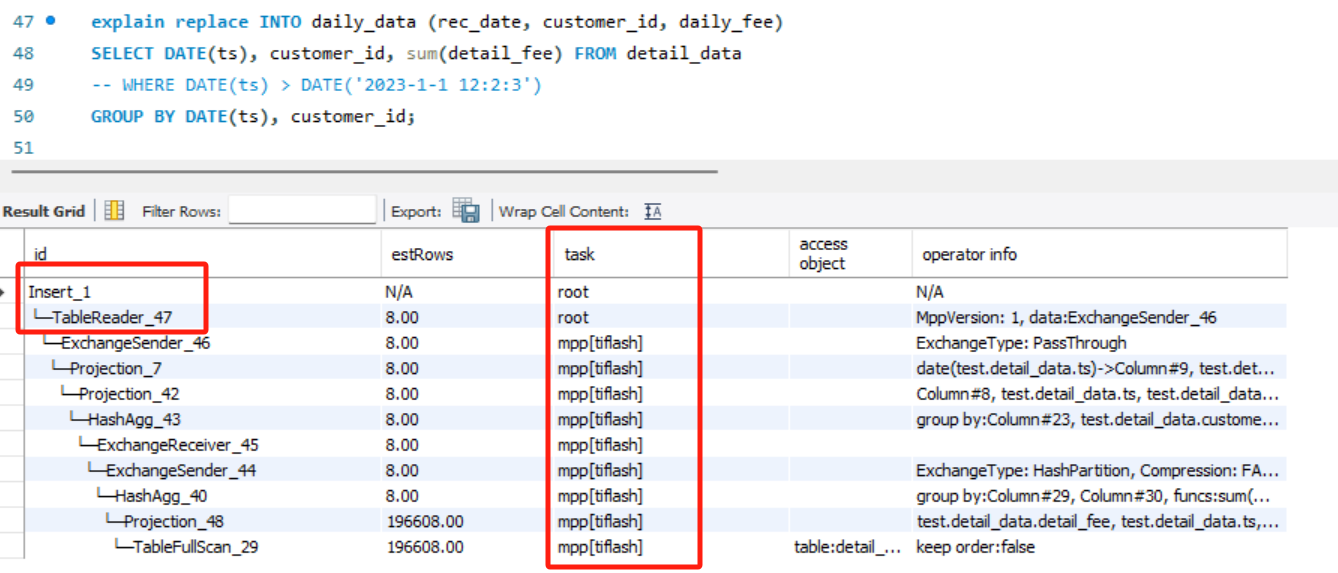
可以看到查询结果也是task这一栏 上面是几行root,下面全部是mpp[TiFlash] .
假如你负责写入的这个表的指标设计的比较复杂,单独一列的计算都是一个复杂的聚合计算,如果要做到按列刷新,可以使用 insert into ... select ...on duplicate key update的形式来按列更新。 执行计划如下:
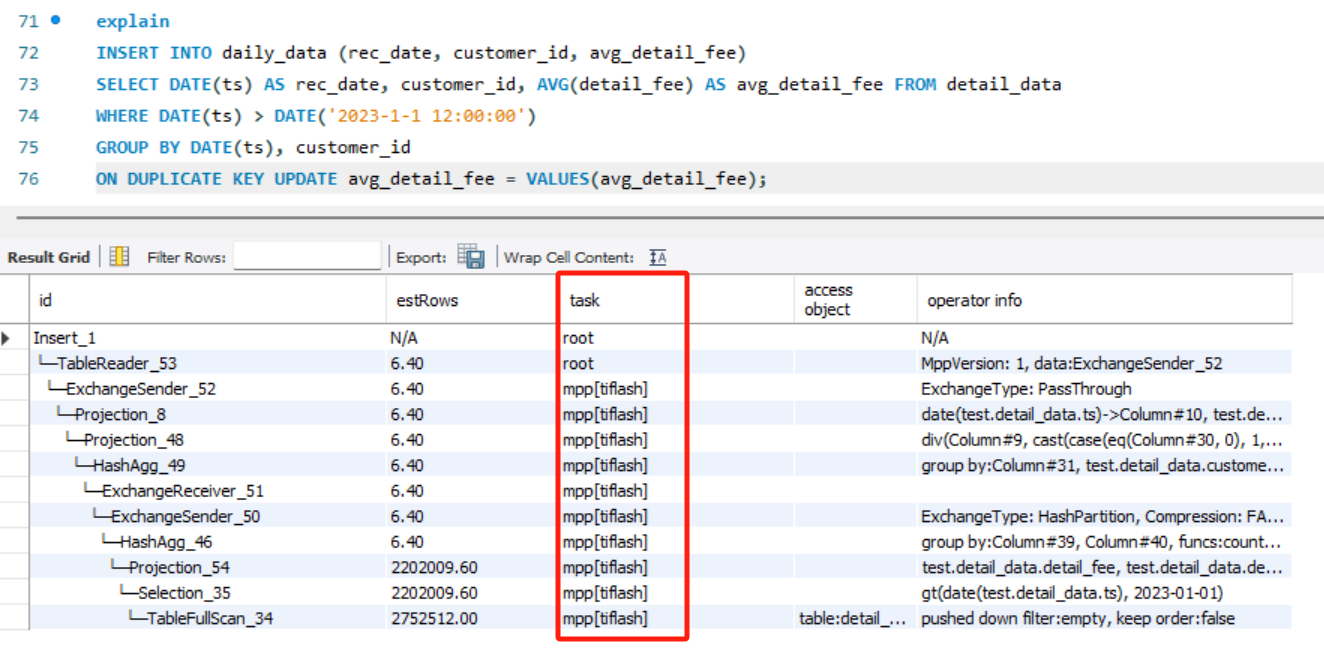
可以看到也是上面这个形式。
对于这个功能,我觉得是因为文档举例介绍的范围有点窄,所以是被低估的。 在 insert into ... select ...on duplicate key update 这种按列更新也能支持的情况下,可以做很多事。 哪怕不用于对付高并发,做报表的跑批更新也能用到这个功能,而且完全发挥了列存和行存这两者的优点。做到列存算,行存插入/查讯。 可以说是手动支持了物化视图的刷新。使用确实没有物化视图那么友好,但大致的物化视图功能,通过手动刷新麻烦一点是马马虎虎能做到的。
3,TiFlash在整个TiDB架构中的一些思考
TiFlash是通过raft learner的角色加入原有的TiKV raft组,从TiKV同步数据到TiFlash的。
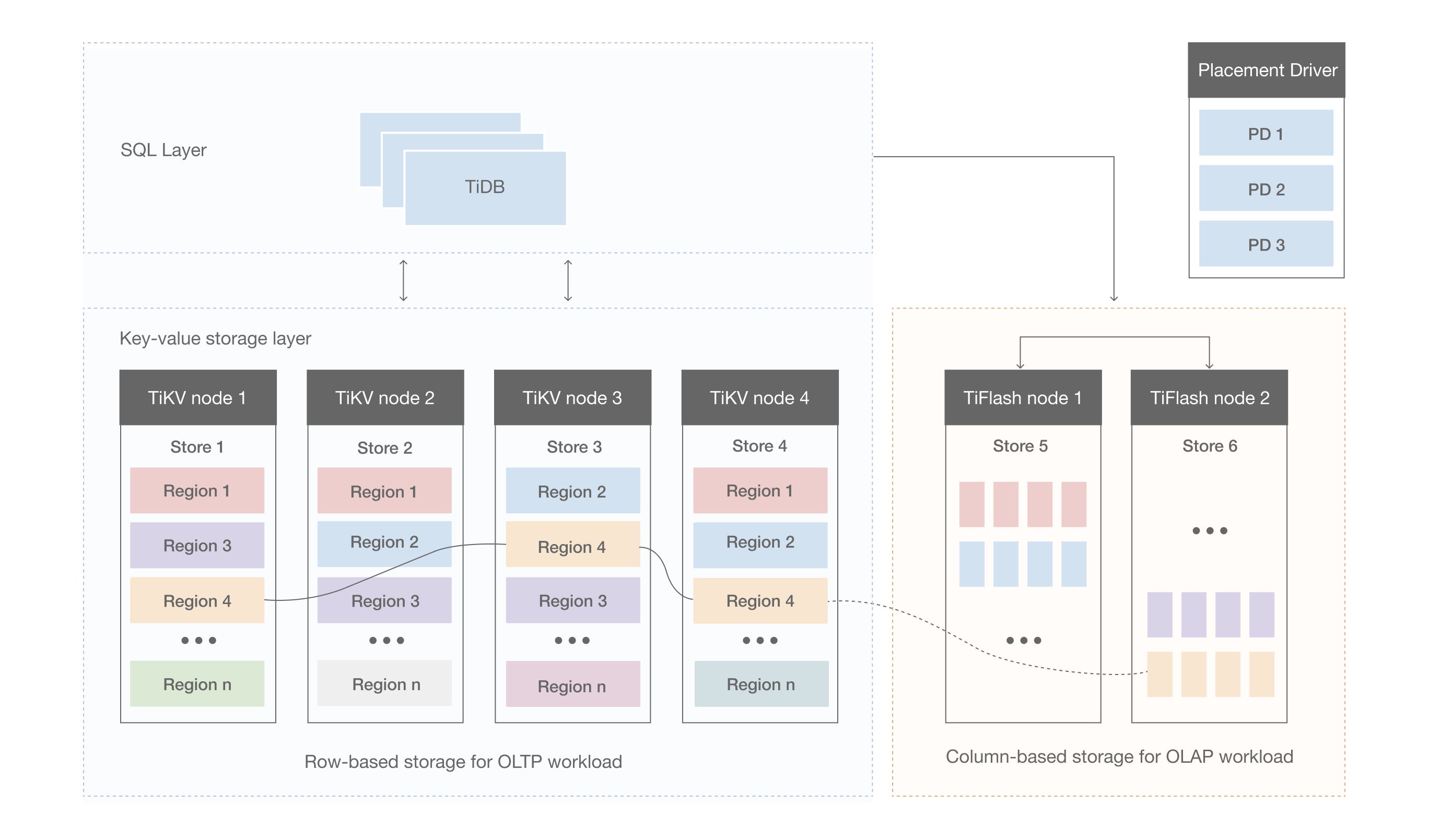
所以显而易见的一个问题是TiFlash稳定性依赖TiKV的稳定性。即,在整个TiDB的体系中,应该先保证TP业务的稳定,在考虑AP业务。 如果TP业务本身已经不怎么稳定的情况下,想通过添加TiFlash节点解决TP业务面临的一些问题,对于新手来说是比较困难的,我在论坛上经常见到的很多对TiFlash的负面评价都来源于此。 本身的TP业务就不太稳定,已经面临各种各样的慢查询的,希望通过添加TiFlash这种列存节点来尝试优化,如果是聚合计算这种TiFlash这种本身擅长的场景,可能确实有用。 不过造成这种情况的大部分用户,不能很好的区分这点,那么眉毛胡子一把抓,TP和AP业务混合负载没有在各自擅长的节点上运行的结果,往往会使得情况恶化,优化的难度也变高了。 给人的感觉就像是添加了TiFlash反而做了负优化。对TiFlash而言这是个比较冤枉的评价。
3.1 渐进式的尝试TiFlash是个很好的实践
其实我自己的实践,无意中就是这种渐进的尝试。
我首先是从建立好了PD TiDB TiKV这三件套,通过资源管控等一系列优化,保证了这三件套运行的稳定,然后才开始尝试TiFlash节点。 TiFlash节点在没有任何负载(0副本0请求的初始状态下)的时候只要几百M的内存就能运行起来,而我使用的4c8g的配置也远低于文档要求的最低配置。 我当然不是鼓励大家都不按照文档推荐的来做,我强调的重点在于如果数据集小于1T,大致在300g左右,那么从试用/尝鲜/体验的角度讲,4c8g这种低成本的机器就可以开始用TiFlash了。 大家可以低成本的用起来,按我上面说的自己参数针对聚合计算的sql尝试着做一下,具体运行的速度能提升多少,大家也就有数了。 那么后续无论是继续尝试更大数据集的聚合计算,还是写报告向老板申请更好的资源,都有依据。不必因为成本的原因,没有办法进行从0开始的第一步。
AP节点的扩展能进行这种渐进式的尝试,意味着无论是在工程上,还是在公司内部的政治上,都能降低背锅的概率。这对于初次尝试新组件/新技术的DBA来说尤为重要。
3.2 更好的实践推荐
推荐李文杰老师( @Jellybean )的一篇文章:《 构建稳定高效 TiDB 多租户系统的方法与实践 》
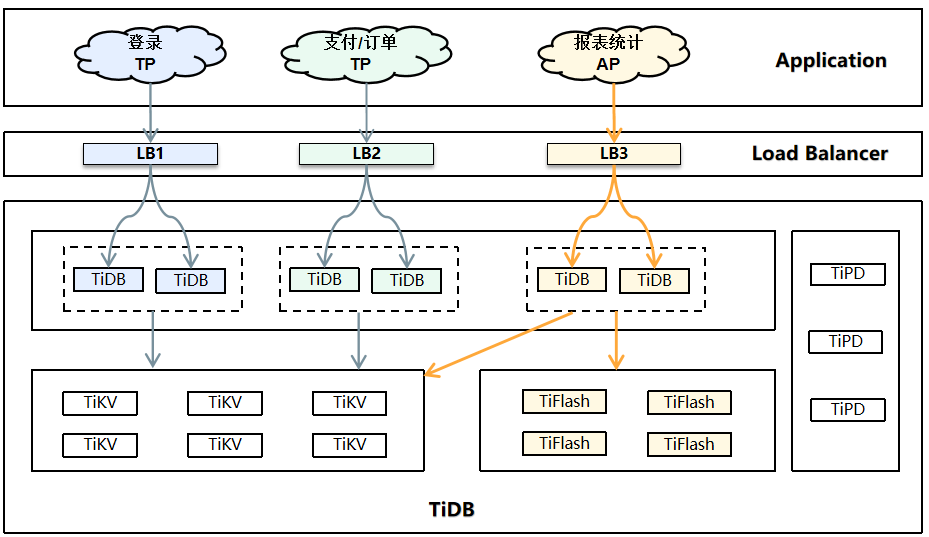
这是我看了以后很有启发的一篇文章。 可以看到每组TP/AP业务都有自己独立的LB,有自己独立的一组TiDB节点,并且TP业务不访问TiFlash。而AP业务可以访问TiKV也可以访问TiFlash。 这样设置的结果,我自己总结了一下,就是 让合适节点运行合适的负载 。 TP业务就应该运行在原有的PD,TiDB,TiKV的三件套上,把AP业务中聚合计算的部分,通过MPP大部分下推给TiFlash做。有些需要查询结果物化之后的表,存在TiKV中,如果没有多层的聚合,对于最顶层的聚合结果来说这部分查询其实是扫描任务而不是聚合计算了,直接从TiKV上读取更高效。
当然小公司/小集群可能没有这么财大气粗,各种业务有独立的LB,和一组独立的TiDB节点。但让TP和AP业务分别运行在各自适合的节点上这个思路仍然是可以实现的。
我的TP业务主要dm同步上游的mysql写入。通过在所有实例上,同时设置global级别的tidb_allow_mpp=OFF,tidb_enforce_mpp=OFF.关闭MPP下推。那只要连接来的业务不做特殊处理都是无法访问TiFlash的。这就保证了现有TP业务不会访问TiFlash。 AP业务主要是通过metabase连接来的这部分查询,而在metabase连接TiDB的jdbc连接串上,我设置了参数TiDB_allow_mpp=ON,TiDB_enforce_mpp=ON,这就保证了通过metabase建立的连接,只要有TiFlash副本,基本都是MPP下推到TiFlash的。个别需要调整的可以通过在sql中添加hint set_var语句级的修改变量,达到不做mpp下推的效果。
当合适的负载运行在合适的节点上的时候,就会产生1+1>2的效果,即使AP计算量很大导致不稳定,因为这些聚合计算设置了强制MPP下推也不会威胁到原有TP系统(PD,TiDB,TiKV这三件套)的稳定。这是对TP系统的托底,是最悲观的情况。
如果没有碰上最悲观的情况,那么聚合计算在TiFlash上运行的更快。两边都做了自己擅长做的事,还能各自独立扩容,也是扩展性和HTAP特性的体现。
4,总结
4.1 优点
4.1.1 速度
TiFlash+MPP对聚合计算的加速效果非常明显,可以轻松比TiDB+TiKV的方式快2-10倍。 即使没有成本,我也没法拒绝TiFlash,要想办法用,这是最重要的一点。大家可以看我生成列的那篇,那篇我用了生成列把一个sql从1分钟左右优化到了10s左右。 但我用上了TiFlash,这个sql不通过生成列优化,基本上也就是3-4s。 我不能说生成列这圈折腾没有意义,毕竟我之前也说过优先保证TP业务的稳定再考虑AP是推荐的做法。但如果我下次再做的话,显然这圈折腾我是不会重来一次的。我会直接考虑TiFlash+MPP来解决聚合计算速度慢的问题,只有发现这个sql是个扫描任务的时候才会考虑是否用生成列。
4.1.2 数据同步
在我这个5-600G的数据规模,能提供的成本也就这点的情况下,如果要再找机器弄专门的AP分析库,是基本不可能做到的。 而且存在同步链路,那么这个同步链路其实是日常维护的大头。这点我相信做AP分析的应该深有体会。数据只要进到库里,无非多聚合几次肯定能算出来。同步链路出问题导致报表出不来是日常维护的大头,而且很不可控,都是突然袭击。 在TiDB体系下,这个同步的问题交给raft协议来保证,还能提供一致性读取,TP和AP业务如果运行在各自擅长的节点上,还能实现2种业务的适当隔离和单独扩展,简直不要太友好。
4.1.3 数据核查的简化
能提供一致性读取,也就意味着从TP到AP的数据核查会变得更简单。 如果是从TiDB同步数据到一个专门的AP库上,那么出现数据核查的问题,要从AP库上查起,检查同步问题,最后对到TP的库上,这样查一遍才算有个结论。 TiDB体系下能提供一致性读取对数据核查就非常友好了,如果怀疑TiFlash的计算结果有问题,我只需要去掉MPP下推,让这个聚合计算的sql去TiKV上算一下,看看结果如何,起码就能大致解决TP到AP之间的核查问题了。 对于已经已经运行了一段时间的老报表这个问题可能还不算突出,但是新需求新报表,当看报表的人向你提出核查的时候,其实你很难拒绝。毕竟报表的“报”字,就意味着看报表的人,往往决策能力比你强,在具体业务上的话语权也比你大。
4.2 缺点
4.2.1 资源压力大
算的快了就会尝试更大的数据集,更复杂的计算。这是人性,会不自觉地开始这么做。我也是这样。 那么很容易就会遇到内存oom的问题。落盘还是执行计划种的estRows估算,这种两种方法都可以酌情使用。方便写这些sql的人能理解,他们正在处理一个多大规模的数据。 另外还要对sql运行的并发程度有个预估,其实跑批的聚合计算任务通过查询结果物化+算子落盘是会有个比较好的运行结果的。 怕的是某些本来可以做一些缓存的偏向TP的任务,发现执行速度快了以后也不做缓存了,直接高并发的下推给TiFlash做。 对并发数还是需要一个预估的。不能预估初期就优先尝试查询结果物化+定时刷新。或者干脆定期查好了放redis之类的缓存里面去。
4.2.2 混合部署后的管理难度很大
我配置虽然很低,但是能用的一个主要原因,我觉得就是存储引擎无论TiKV还是TiFlash,他们之间都没有混布。 假如配置很低,存储引擎无论如何不要混布,TiKV和TiFlash最好都独享一台机器。TiDB和PD可以放一起。 这样能较好的保证整个集群的稳定性。






